
Olá DBAs, a vida tá boa?
Hoje vou mostrar para voces algo que chega a ser até engraçado, sobre o quanto devemos ou não confiar na inteligencia artificial nesse momento pra nos ajudar com problemas do dia-a-dia. Neste caso especificamente, eu fiz uma pergunta ao Google, sobre como podemos alterar o nível de redundancia de um Diskgroup no ASM, e a resposta vai te surpreender.

Eis que por essas andanças da vida, tenho visto cada vez mais clientes que usam Engineering Systems, chegando aos seus limites de espaço em disco. Sim, já passando dos 90% de uso de disco, e em certos casos até pior, já “respirando por aparelhos”.
Como consultor, as vezes chegamos para atuar já com essa situação em estado crítico. A primeira pergunta que vem a nossa cabeça é: Isso não aconteceu de um dia para o outro, o alerta tá aí faz tempo. Porque ninguém fez nada antes?
Esta pergunta tem várias respostas, desde falta de planejamento adequado, até retardo de gastos o máximo possível, e entre essas duas respostas, existem diversas outras que podemos escutar. Nenhuma justifica expor seu negócio dessa maneira, e como costumamos dizer, é raro mas acontece muito.
Neste momento, precisamos usar da criatividade o máximo possível verificando dentro das possibilidades, qual seria a solução de contorno para dar tempo para o cliente finalmente planejar e executar o que precisa (nesse caso adquirir mais espaço) sem uma interrupção dos negócios.
Todos sabemos as saídas padrão:
- Liberar espaço no FRA e/ou alterar redundancia e retenção;
- Ganhar aquele espacinho na UNDO ou TEMP caso estejam subutilizados;
- Shrink de segmentos;
- Falando especificamente de EXA, usar HCC ou outro método de compressão;
- Reorg do database…
E por aí vai. Existem opções? Sim, diversas. Todas são eficazes? Na maioria dos casos sim. Elas são doloridas? Sim, sempre.
Não existe almoço de graça, e existe um preço a se pagar também pela falta de planejamento ou de ação. Voce pode achar que esse preço nem sempre é traduzido em dinheiro, mas a depender do que isso pode ocasionar ao seu sistema, pode sim ser traduzido em dinheiro.
Pensando nisso, eu tive uma idéia esdrúxula e estapafúrdia, mas que acometeu minha mente e eu gostaria de saber mais sobre. E seu eu alterasse a redundancia do meu diskgroup de HIGH para NORMAL?
Abaixo uma ilustração só pra voce lembrar como as redundancias em questão funcionam.
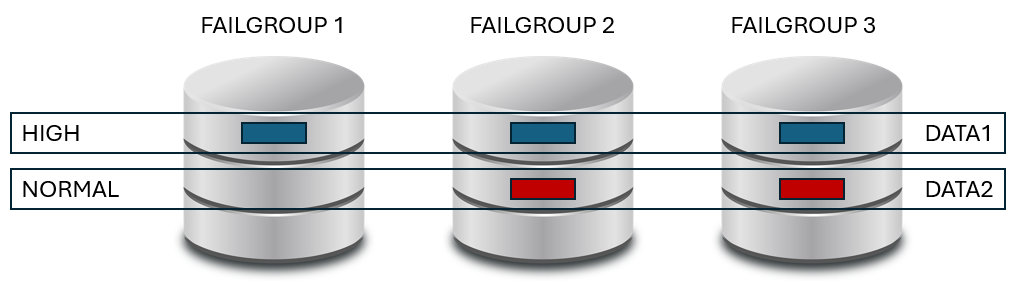
Isso a grosso modo e com um cálculo extremamente apurado e em papel de pão significaria o seguinte:

Em teoria, seria somente a liberação dos blocos na segunda camada de redundancia pelos controles do ASM, ou seja, ao invés de ter 2 cópias dos blocos originais, eu teria somente 1 cópia, liberando a terceira como espaço livre. São mais ou menos 170GB por Terabyte de disco. Acho que dá pra dar uma respirada.
Abram sua mente! Não to pensando nisso por economia a despeito do risco. Sabemos que ambiente de produção deve estar o mais protegido possível, mas no caso onde a situação é crítica e voce precisa “salvar” o seu ambiente de uma parada, seria de grande ajuda até que as devidas soluções fossem tomadas. Nem precisava ser uma alternativa liberada pra operação do DBA, que fosse um procedimento da própria Oracle, a ser feito somente pelo time mediante chamado e recomendação, enquanto negociam um novo Exa, ou adição de discos no próprio Exa caso não seja FullRack.
Polêmico? Talvez. Eficaz? Eu acredito que sim. E voce pode e está no seu direito de discordar.
Agora vamos ao que aconteceu. Decidi perguntar ao Google se era possível alterar a redundancia do diskgroup no ASM. Eu nunca tinha me feito essa pergunta, mas já imaginava que não, pois imagine se ao invés de alterar de HIGH2NORMAL, a gente quisesse fazer o contrário de NORMAL2HIGH. Imagine a complexidade e lógica de programação por trás disso, além do tempo e do consumo de recursos. Seria extremamente penoso e acho até perigoso a depender de como fizessem o processo. Mas de HIGH2NORMAL, seria somente liberação de blocos ao meu ver, a exemplo do que é feito com os blocos de UNDO o tempo todo.
Sem pensar muito e sem preparação alguma, eu lancei a braba no google. E a resposta me surpreendeu:
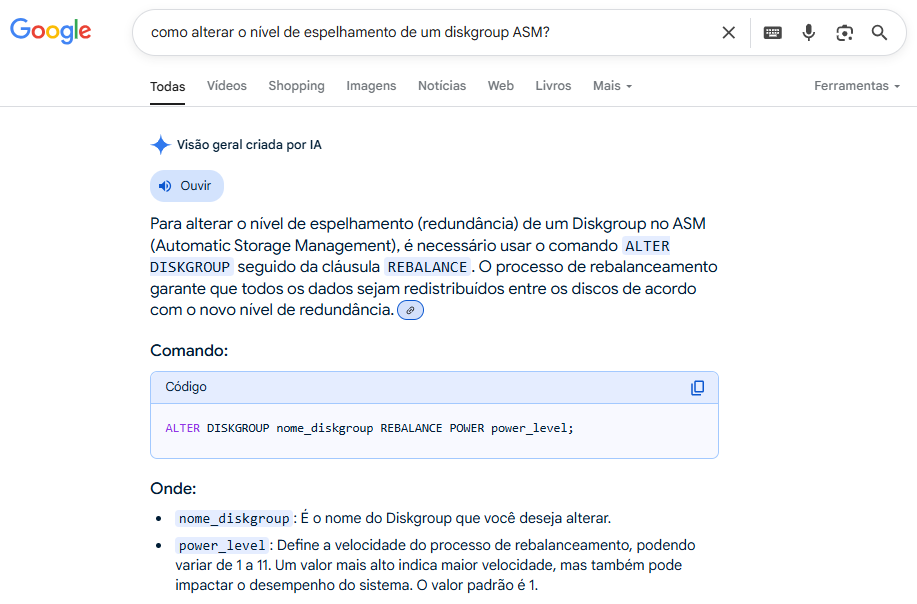
E ainda deu os comandos de exemplo para fazer essa alteração:
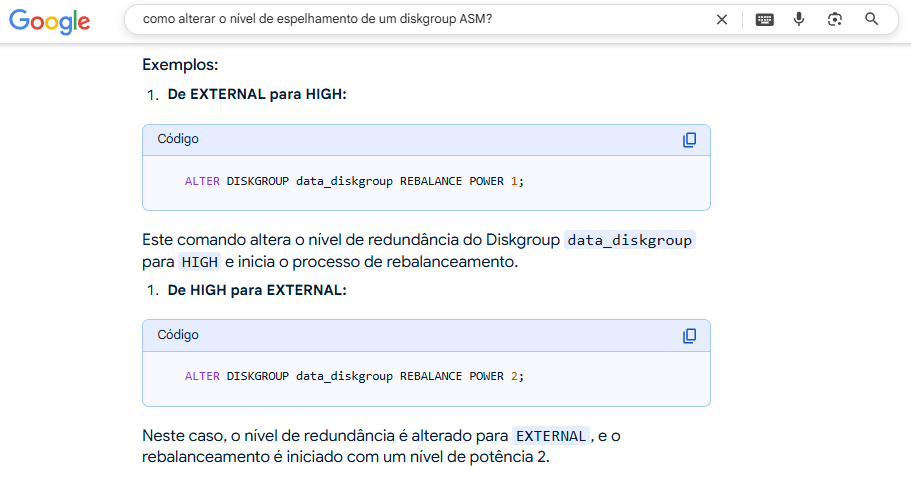
Minha reação imediata ao ver isso foi aquela torcida de boca seguida de um “Hein?!?!?!”. Eu jamais havia ouvido falar ou lido sobre que o rebalance podia ser usado para tal.
Decidi então ser um pouco mais específico na pergunta:
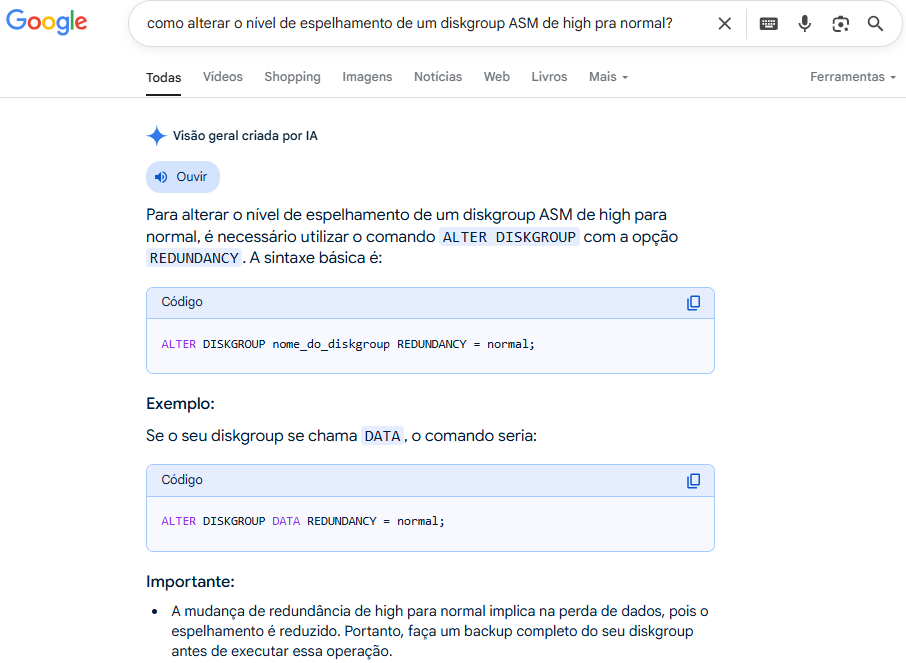
Achei muito, muito interessante, eu realmente não imaginava que era possível fazer isso. Mas desconfiado que sou, decidi começar a checar a documentação mesmo ao invés da resposta que a IA me deu. De cara eu fui na documentação do 19c, nem chequei nas versões anteriores, pois se não tiver na 19c eu duvido que havia nas versões anteriores.
Voces estão vendo na imagem acima a cláusula “redundancy” pro alter diskgroup? Pois é, nem eu.
Uma das fontes que a IA usou é “https://www.oracle.com/ocom/groups/public/@otn/documents/webcontent/3518404.pdf“, que eu chequei e em momento algum deste DOC existe a síntaxe mecionada pela IA.
Também dei uma geral no DOC “https://docs.oracle.com/en/database/oracle/oracle-database/19/ostmg/admin-asm-diskgroups.html#GUID-76B31808-7017-4299-8CC2-EDD9FFEC4B37“, e nada encontrei sobre uma síntaxe como essa.
Também procurei essa informação no MOS, e nada encontrei dizendo que era possível. Encontrei algumas referencias onde se fazia a mesma pergunta, para diferentes Engineering Systems (EXA e ODA). A resposta mais clara no MOS que encontrei foi referente a alteração de NORMAL para EXTERNAL no DOCID
Can a Diskgroup be converted from Normal Redundancy to External Redundancy in 19c (Doc ID 3057056.1)
E essa reposta diz o seguinte:

Em outros documentos também no MOS, todas as respostas são unanimes ao afirmar que essa alteração não é possível. O Máximo que voce pode ter é utilizar o Método FLEX pra redundancia, o que não é especificamente a alteração de um nível de redundancia para outro como estamos aqui a pesquisar, mas sim de ter mais de uma redundancia onde a orientação é por database e/ou por groupfiles, não por disco, e voce pode isolar databases e/ou groupfiles em redundancias diferentes, mas isso é assunto pra outro post e necessariamente não reflete o cenário de calamidade que eu estou descrevendo aqui.
Em resumo, todas as vezes que voce receber a resposta da IA do Google, chatgpt, não importa o que seja, não confie cegamente. Check, doublecheck, converser com seus pares, tire dúvidas, e não saia igual vaca braba aplicando direto sem fazer uma pesquisa de confirmação (e de entendimento) antes de implementar ou repassar a informação.
O próprio Google desconfia de si mesmo e fala pra voce ficar cabrero com ele:


Ou seja, ao que parece, diversos documentos tem as estruturas de “alter diskgroup” e também existe o parametro “redundancy”, mas na criação do diskgroup, não no “alter”. Ao analisar e tentar entender os padrões, a IA entende que estas estruturas podem ser unidas, e que este comando é possível, quando não é.
Então fica esperto cabeção, use a IA a seu favor, não contra voce. Não vai ficar desseminando informação técnica sem uma apuração decente do que voce está falando, só porque a IA te disse que existe. Senão voce vai ser a vózinha do whatsapp que repassa fake news nos grupos de Whatsapp da família…huahuauhauhauhahua!
Fiquem a vontade para fazer quaisquer pontuações caso já tenham vivenciado algo do tipo.
Essa é a dica 0800 pra voces desta vez.
“Saber das coisas vale ouro. Compartilhar esse conhecimento não tem preço.”